A Lambda Architecture for Social Insights
At a SaaS company

⚠️ Parental Advisory: For Technical Audience 😸
A decade after social networks foundation, Facebook/Instagram, Youtube, Whatsapp, Twitter, were looking for serious revenue, and their monetization strategies allowed third-party initiatives from technology partners, which skyrocketed the marketing business.
Context
Working for a social-engagement technology SaaS platform, I had one of the most fun times as a developer, pairing with the founders.
For developers, we care about:
a healthy codebase: Clean Code and SOLID principles fully applied 💪
chances of solving cool challenges from ground zero 😍
touching cool architectures and re-engineering parts of it 🚀
This project had it all, including all the use-cases for new technologies.
The codebase had ~500k LOC, distributed in ~15 repositories, after 5 years of evolution, growing solutions around the marketing and digital agencies fields. Ingesting, processing and serving analytical insights and enabling actionables.
This was a SaaS platform that we evolved organically, every feature and product was built with a deep mind on business alignment, reusability, performance and delivery costs.
What’s an Engagement platform ?
More ore less this diagram says it all:
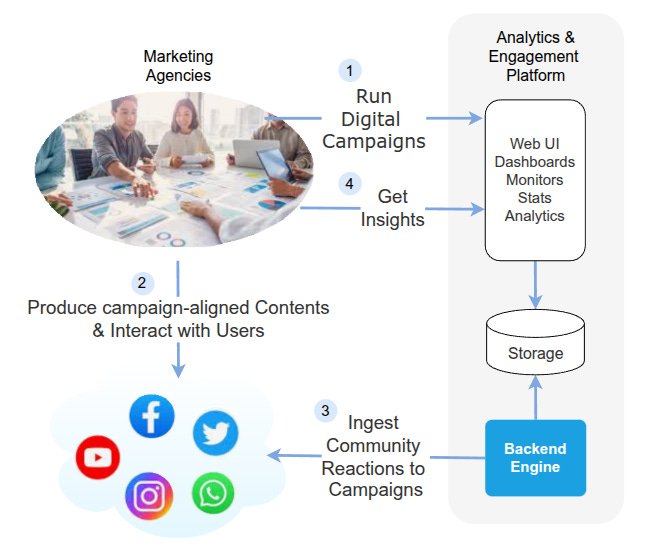
️These platforms had proved to help companies improve revenue: by repositioning brands, increasing loyalty, augmenting target visibility, measuring campaign results, retro feeding brand’s products with meaningful insights on matters of stats and sentiment analysis.
Focus: backend
The Backend Engine blue box is where you’ll find me, there’s a lot more complex things, zoom in to check how it was internally built:
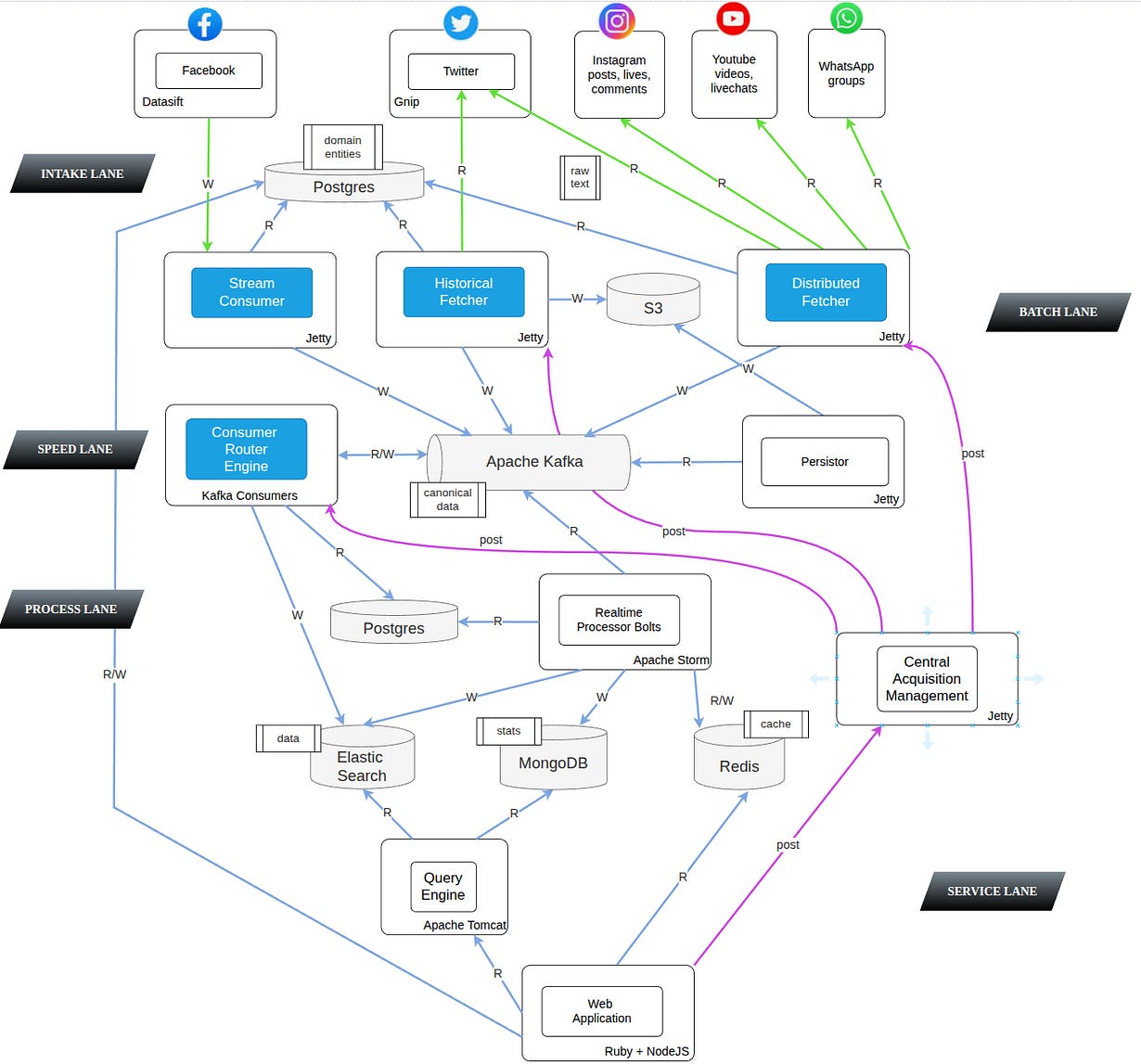
The Ingestion Pipeline
Basically there’s a WebApp UI managing marketing campaigns, facing User requirements in term of scope, boundaries, targets, time-ranges, events, locations, tags, for self-executed, campaign-controlled, social activities in any given social media. A Central acquisition manager aware of the input model changes, simply triggering individual engines at the acquisition layer, to refresh the model and apply any changes into their ingestion schedules. A distributed fetcher using semi-public social-network’s APIs for “live” contents, an historical or “past-tense” fetcher, and a stream consumer. Conceptually they’re all “ETLs”… just +10 repositories on around ~200k LOC in total, so not really an average database ETL, but more of an ingestion pipeline.
The Blue Boxes
There were many other components, but the blue boxes are the problem/solutions I tackled and I’ll cite in this article :
an Historical Importer for Twitter and Instagram contents
a Distributed Fetcher for Twitter, Instagram (Posts, Lives, Comments) , Youtube (videos, live-chats) and Whatsapp (groups)
a Stream Consumer for the Facebook firehose (posts, comments)
Problem: Historicals
We needed to provide historical records for twitter-based engagement campaigns. At the time, Twitter sold historical data to Gnip, so you’d buy thru an API, specific localized amounts of data from their Powertruck product. Required to ask preparation for it, to check readiness, to fetch files individually, then we had the load and transform on our own infra.
Challenges and Goals: ACID 🧪
We needed an ETL-like batch process cautiously buying, dealing with semaphores, errors, formats, both of third-parties and of our own evolving infrastructure. Every action and data must be handled atomically and idempotently.
⚠️ Any error, wait, unresponsive or unexpected status must be automatically and/or manually handled, by retries, and it’s data not lost, and if killed, the process must automatically and easily continue from a savepoint, because 💰 money. The process needs to be ACID to be able to scale without errors.
Scope
There were more upcoming batch jobs with the same concerns, so we had to solve it in 1 same component. Not a typical DWH ETL SQL-based tool, that grows overhead complexity and performance flaws. But more like just a smart component design.
The Solution implemented
The first thing is to build an abstract persisting state-machine component, that reacts to a pre-configured set of semaphores and monitors agnostic handlers, for every definable state.
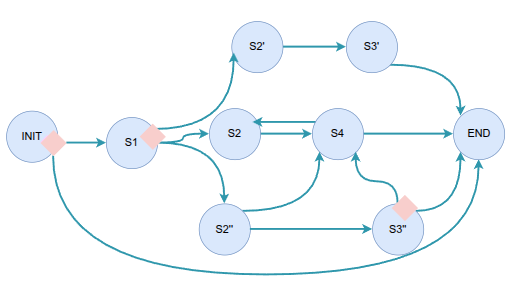
Second, we need to fragment the ETL into these atomic and idempotent handler’s model. Here’s an end-result diagram on all states, handlers and storage dependencies where they’re reading, writing and signaling:
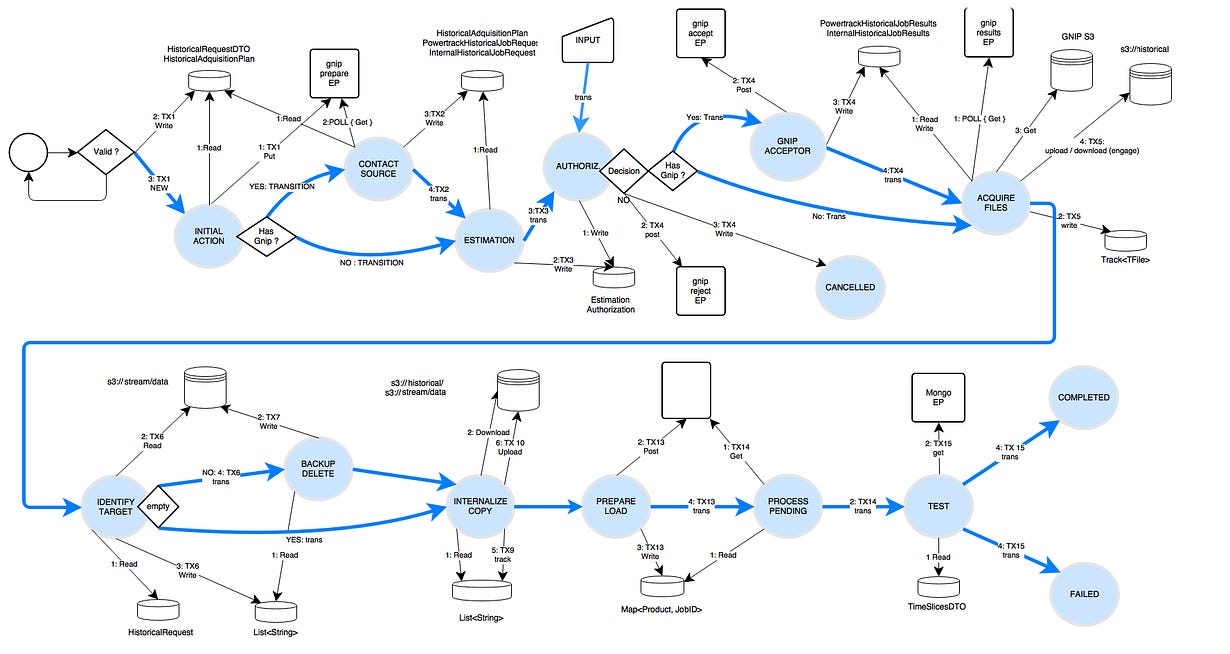
Then just code every state handler dealing with different actions and signal outcomes, linking inputs to outputs thru the state-machine storage. Not something you’ll vibe-code your way out of it 😝
The ETL’s execution was triggered automatically for self-assisted campaigns that required it. Monitored by DevOps thru an API that could CRUD it entirely for troubleshooting.
The details are for another article, but it’s just Java code and Open source libraries, frameworks, tools, mixed up with lot of Testing and Automation efforts, with obvious NDA issues. No more than 2 repositories, ~200 classes, and 4 weeks of striking keys. (State Machine + ETL)
Problem: Distributed Fetcher
Work in Progress…