Building a NRT Nudity Detection system
At a massive social website

⚠️ Parental Advisory: For Technical Audience 😸
Context
Working for a popular social website among spanish speaking countries, with 10ths of millions in daily visits, in all age ranges, from all over latinoamerica. The existing website was a legacy monolith in a single frontend codebase altogether.
A Problem appeared
The marketing area raised an alert: users creating posts and comments with offensive pictures and videos in communities not suited for such. To keep commercial revenue growing we needed to get rid of it.
The goal was set
The company needed to fight back with efficiency and high precision, but without hurting the user-community vibe. The target was contents of adult, gross and illegal nature, showing alongside our sponsors:
restrict user behaviour, allow a human content moderation step
block suspicious posts before being published (in realtime)
remove new and old contents
Scope of the API contracts
We’d handle several incoming platform events:
from Monolith: Media validation before creation
from Website’s API: Reports and Blocks from the Platform Moderation
from Website’s API: Views on Unchecked contents (created before this solution’s implementation or from current integration inconsistencies)
Technical Challenges
Among the obstacles and challenges to solve this automatically was:
public media files (id est, outside our infrastructure)
lack of ML mature enough in this field 👶
the monolith and solution being deployed in different datacenters 😨
a website lacking of transactional consistency 😆
the ever increasing incoming traffic
Challenge accepted 😎
Solution
Components
We built a Java-based semi-automatic content moderation service for posts and comments, exposing Rest API contracts, adding user reports and user-block internal mechanisms to feedback with the community activity.
A Media Analysis application cluster with near-realtime response, it processed videos/images: applied a battery of filters looking for specific chromatic patterns, skin features, and a polygon detection algorithm for nudity trained with specific media, also using other engineering resources like caching, hashing, origin blacklists, already banned pictures, etc.
A Coordinator API server for orchestrating the media analysis components and moderation workflow, and to handle model caching, relationships between metadata, states, results, and the site domain entities.
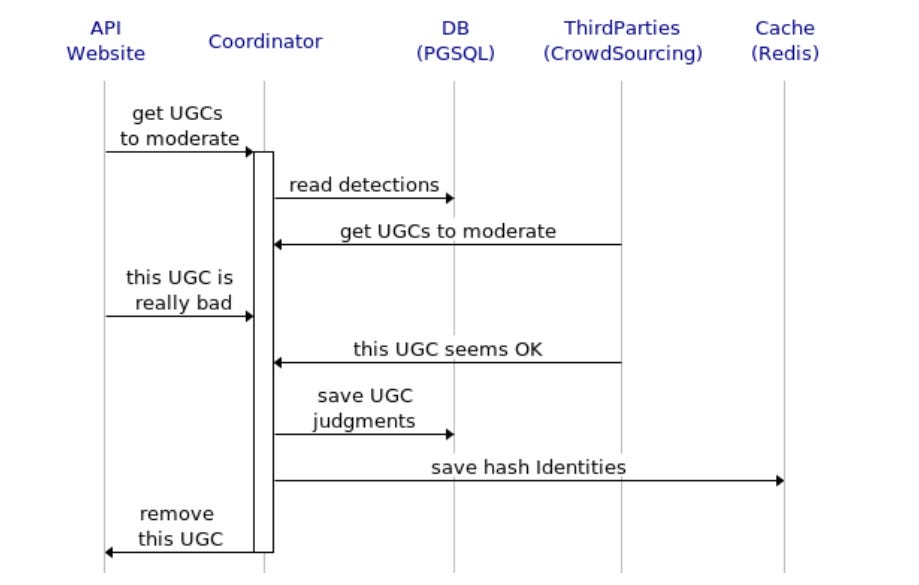
Here’s a realtime request-response sequence, on how I designed the validation of the website events, for new posts and comments:
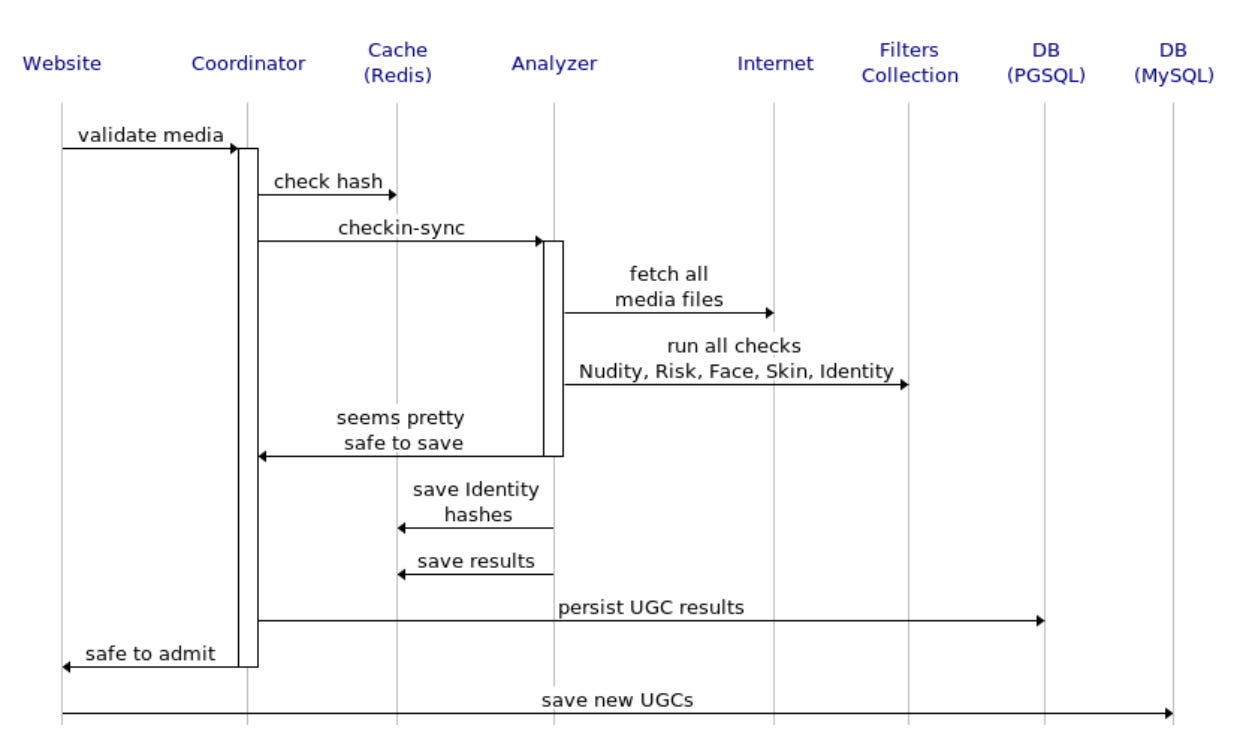
This represents the sequence for the asynchronous integration with the website’s API service implemented outside the monolith, and the view event
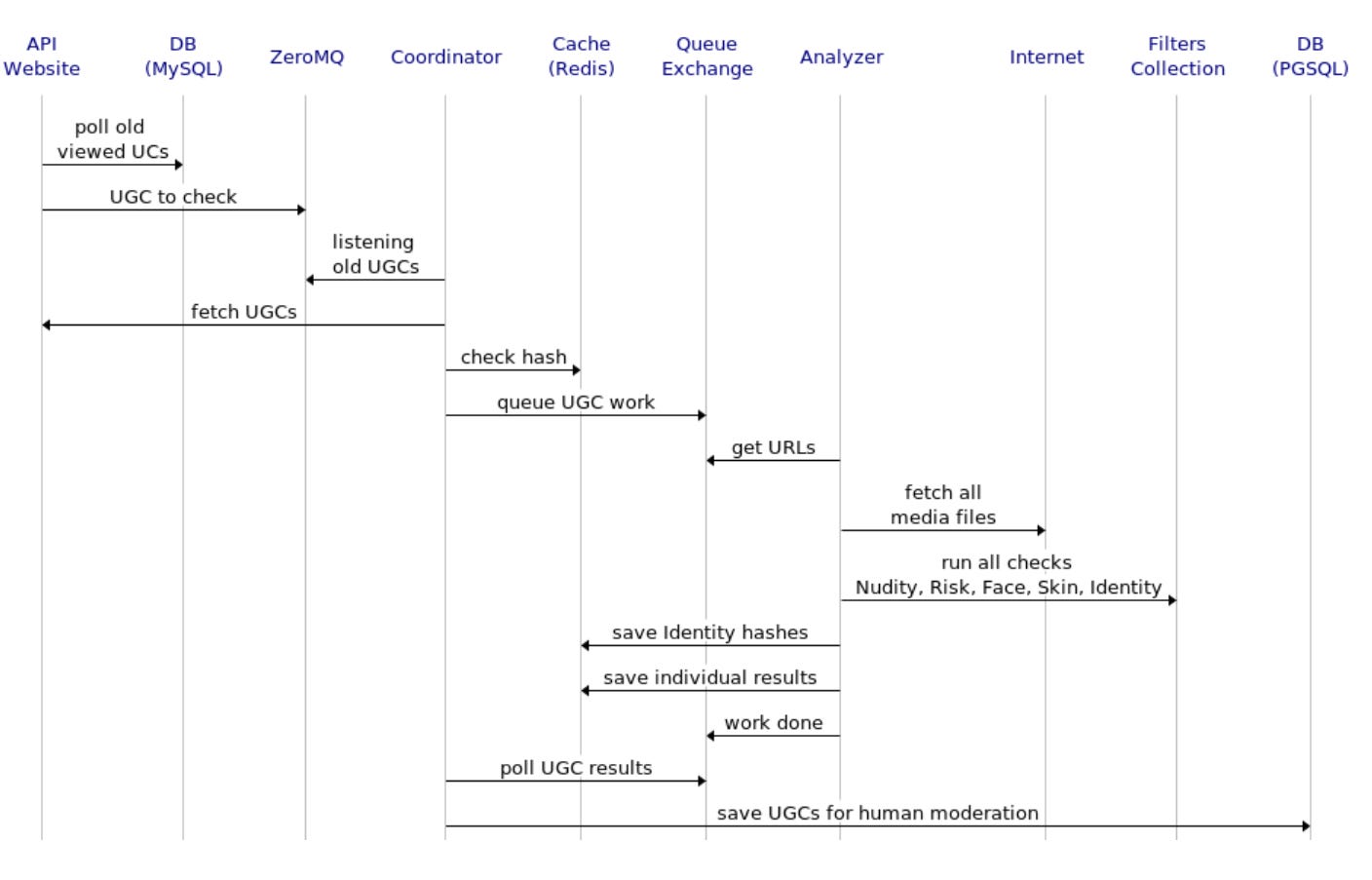
A workflow interleaved automatic and manual tasks between the moderation crew and the media analysis server. Media analysis communication in between the solution and the website monolith was organized into states to play well with a manual decision stage and to orchestrate internal queues, pollers, data synchronization, dependencies to external services, and errors of both human and algorithmic origins.
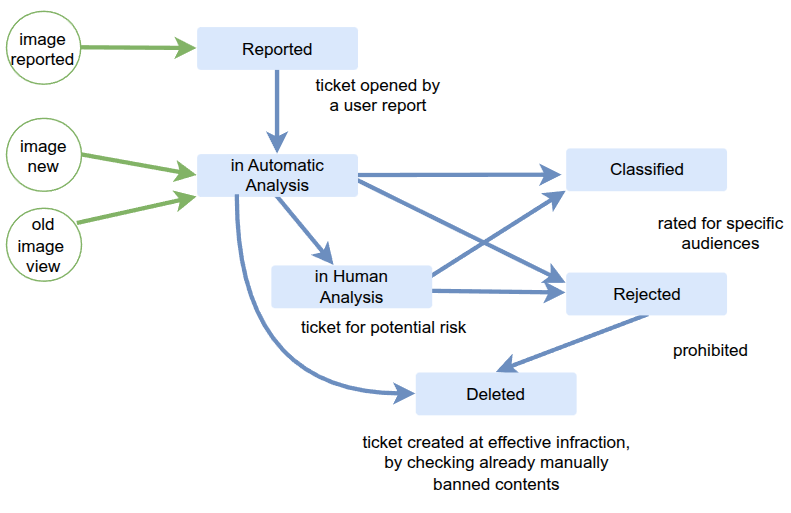
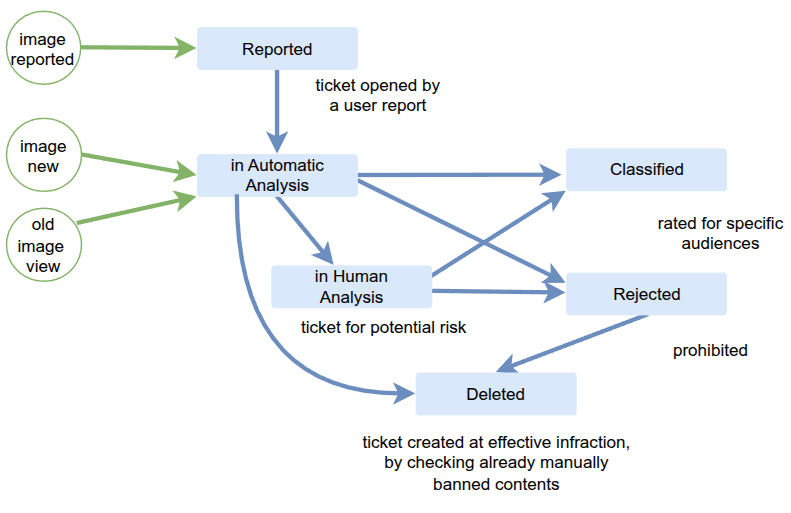
A UI dashboard to arbiter automatically detected cases that were not extreme, allowing human control. Actors were company operators, super users and crowd-sourcing providers, to ban, allow or mark media to match categories for different reaction: deletion, banning, etc.
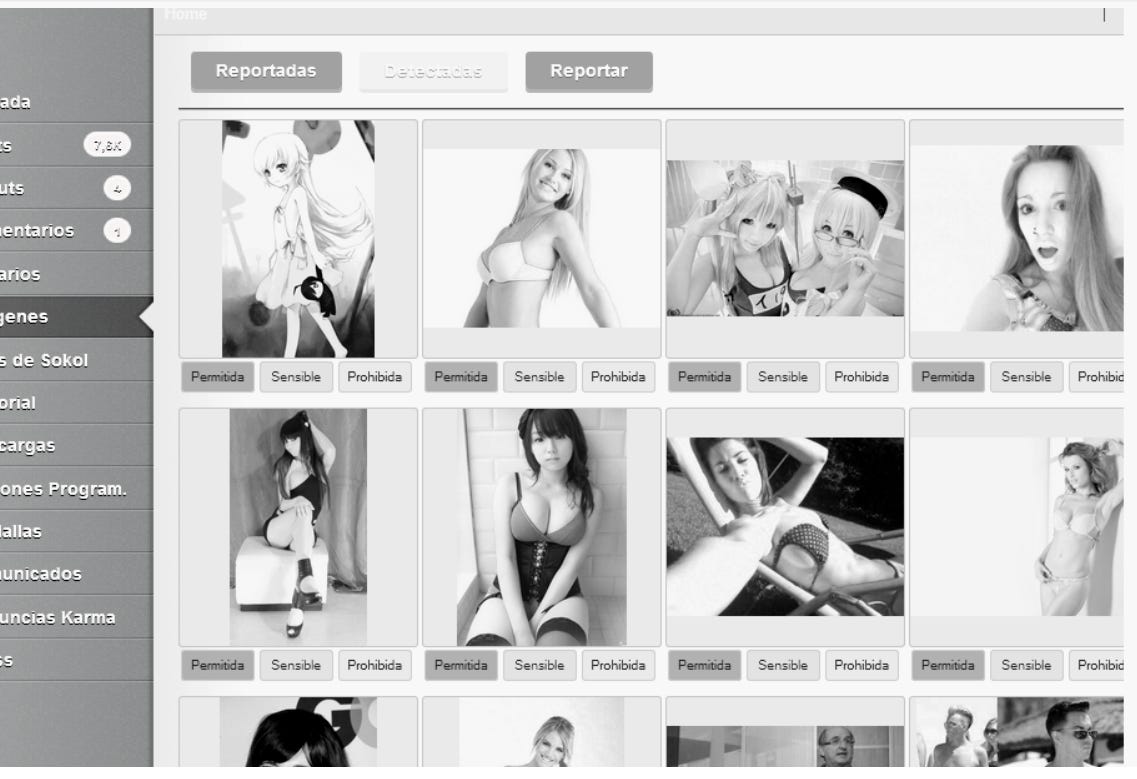
Here’s a sequence diagram on its implementation:
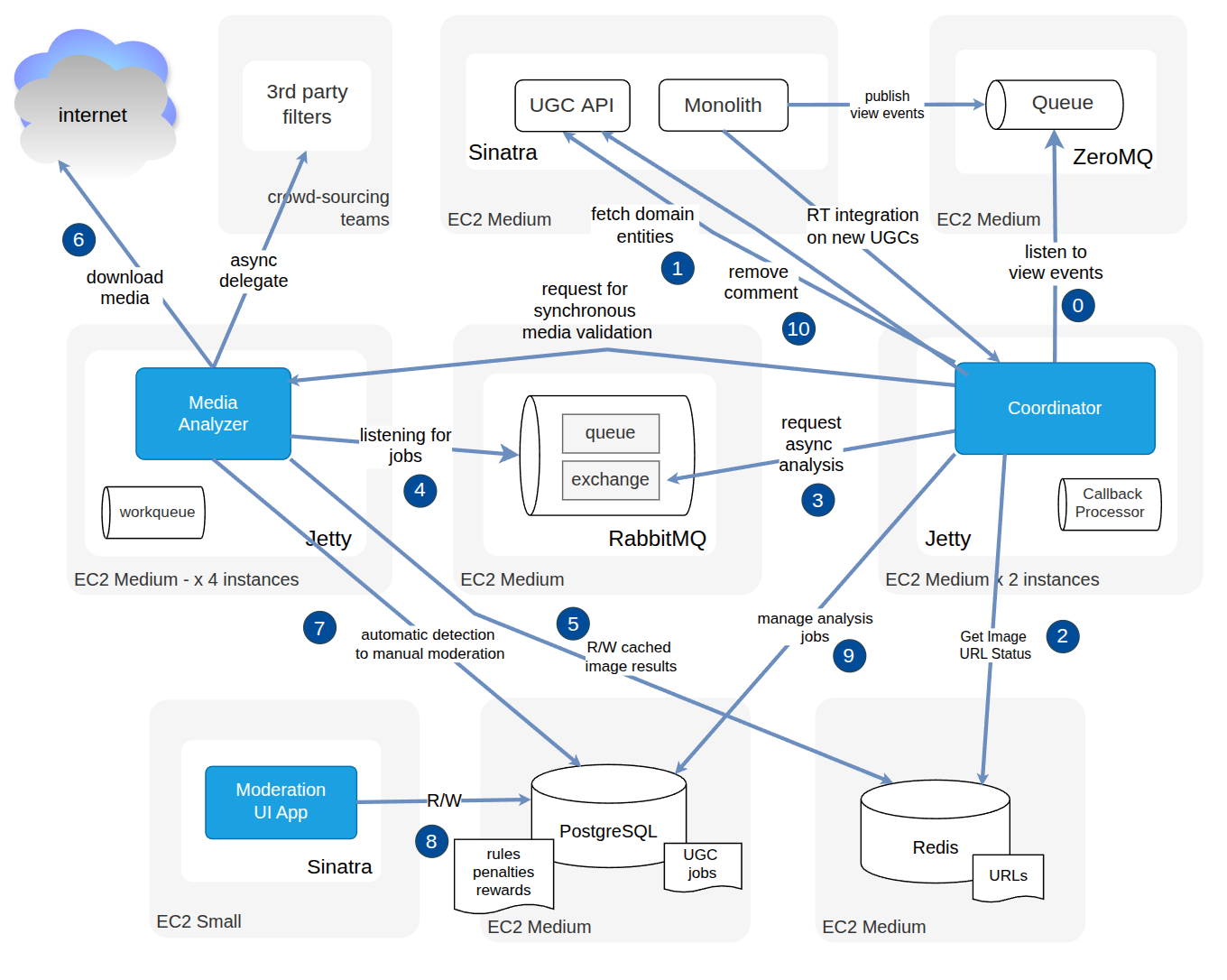
Architecture details
A pair of Java servers for orchestrating and analyzing images, acting in clusters
A RabbitMQ exchange and queues for scaling up image processing
A PostgresQL DB for persisting URL analysis results and UGC fetched domain entities
Redis as a 1st cache for image URLs and analysis results
A Php/Sinatra web UI for arbitring suspected image cases
All communication between the components in a Rest conventional style
A Php Microservice scaffolding the legacy monolith website to deal with the Databases.
A legacy ZeroMQ installation was reused for sharing async events between the monolith and the solution
Here’s a component interaction diagram on how I designed the architecture:
Performance
On average and tunning knobs at specific markers, on a daily basis it processed automatically ~1M posts/comments = ~500k images, banned 20k~10k images, and put another 5k~10k under suspicion for final decision and feedback retraining.
Challenges unaddressed
It worked great labeling a vast majority of media on the edges (very offensive, very inoffensive), but it also failed with a % of false-negatives, and one offensive image cleverly crafted to hack the detection: can turn off business sponsorship, even with 99% of all other true-positive detected contents removed.
Tunning up for more false-positives in hope for curating specific channels was hard. The challenge and complexity was how to reduce the middle range of non-extreme detections, which clogged the human moderation queues with unviable time delays.
There were 3 knobs at play to balance algorithmic efficiency and costs convenience, and all of them played bad with each other.
realtime analysis with synchronous response,
low budget for scaling up,
a threshold to move false-negatives up or down.
Conclusion
The solution performed excellent for extreme edged samples but failed to be perfect on subtle media, and that was the hidden catch we under-estimated in the beginning.
Machine Learning R+D and hardware was costful then and today. Having a system that technically scaled consistently didn’t mean much difference. Even today in the AI and ML field there’s no bullet-proof method that would guarantee 0% of false-negatives analyzing media.
The automation strategy required absolute technical accuracy outsmarting a tsunami of anonymous teenaged users with no incentive to fair-play and no penalties for bad behaviour.