User Segmentation Architecture for Advertising business
in a startup acquired by an Ad Network

⚠️ Parental Advisory: For Technical Audience 😸
Context
In the Ad-Networks era, the market was hugely diversified with all types of complex arrangements between parties in both commercial and technological ways. Media agencies, Ad Networks,Ad Exchanges, were among our clients.
Problem
Our main client needed to maximize the Ads CTR (click-to-rate) metric, so I tackled the profiling of million daily visitors from multiple ad networks, for the business to serve better suited targeted Ads, increasing chance of conversion.
I’ll show you here the Engineering view of the Architecture. The profiling details on how the segments were crafted requires another article
Solution
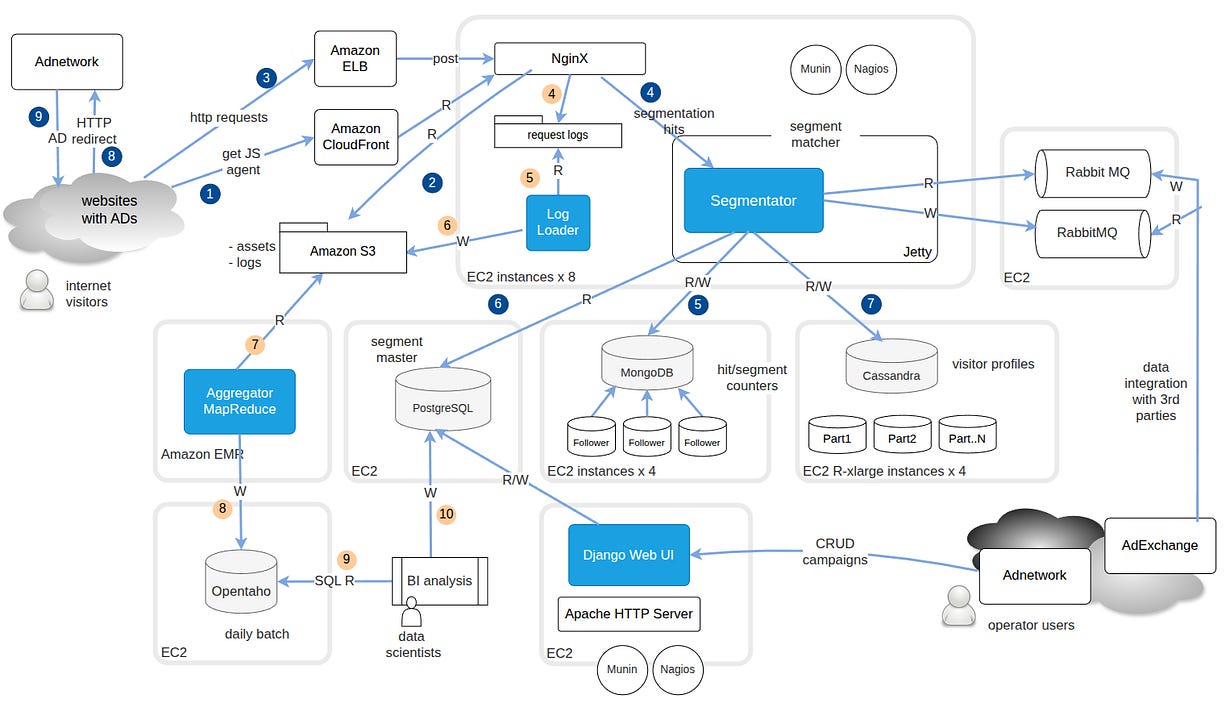
Components
I crafted a solution to play a Data Supplier role in the ecosystem, augmenting data from internet users.
For that I implemented online decision trees, logistic regressions, bloom filters, and offline manual periodic analysis to tune classification ML processes. It had an integration suited to different client needs like an asynchronous communication with queues, synchronous thru HTTP rest, and an ETL batch output.
Every public website having sold a banner placement with an Ad Network: would request our service for a JS agent that collected contextual user & website info and sent it to our backend service.
I designed the interactions between the players like this:
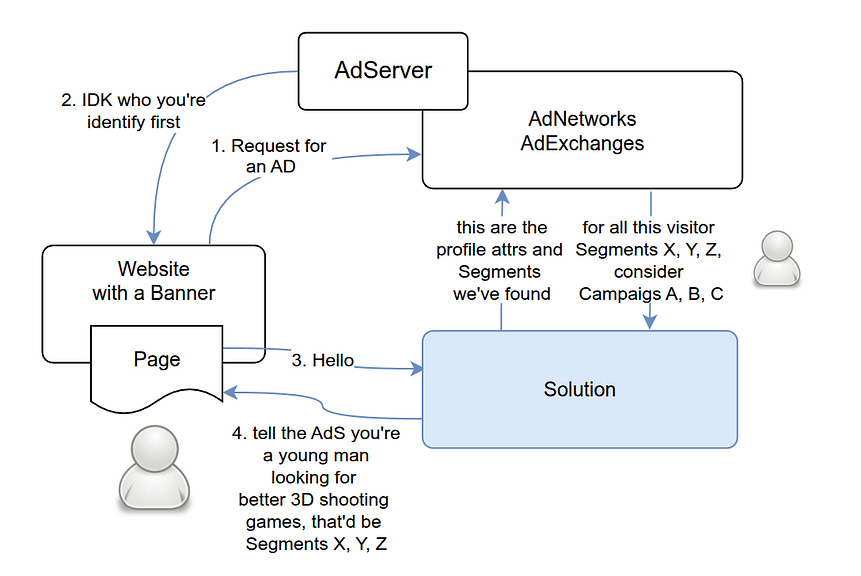
Architecture details
A Spring/Java application cluster, thru Jetty behind an Nginx reversed proxy, for receiving the internet hits from ad-colocated websites
MongoDB for saving user tracking history and counters, cluster deployed in a leader-follower fashion.
A Python/Django UI web application for clients defining segmentation, matching criterias and activating user-targeting campaigns.
PostgreSQL for segments, campaigns and sharing data with the UI Web Application.
Cassandra for storing user’s time-decaying weights on visitor profile’s time-sensitive properties
A MapReduce job on EMR to aggregate keywords and an ETL to load a star schema, for a DS to query for insights
RabbitMQ for the async integration with clients, a pair of inbound/outbound queues to exchange requests metadata with user segmentation.
Here’s an interaction diagram on how components and dependencies were playing their roles, (1,2,3..) enumerated the segmentation flow:
Performance
The backend service app, received ~100K hits/sec. on a daily basis, processed the request reading all incoming parameters, made it’s own inferences, read history tracking, identified users, retro-fed own data about it, and responded synchronously, at <100 ms latency, with a page-redirect sending custom-defined segmentation data to our clients. I could provide location, age, sex, language, categories, with different precision.
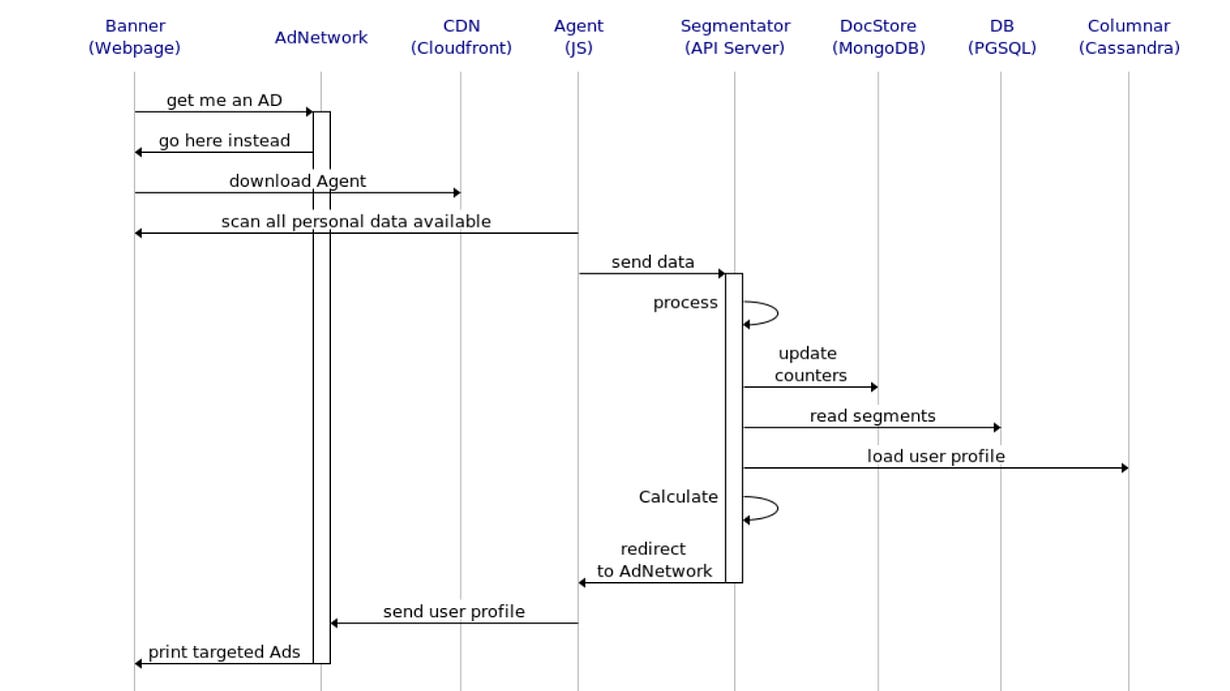
To serve Segments, we designed a sequence on the overall integration between a WebPage, the Ad Network and our solution:
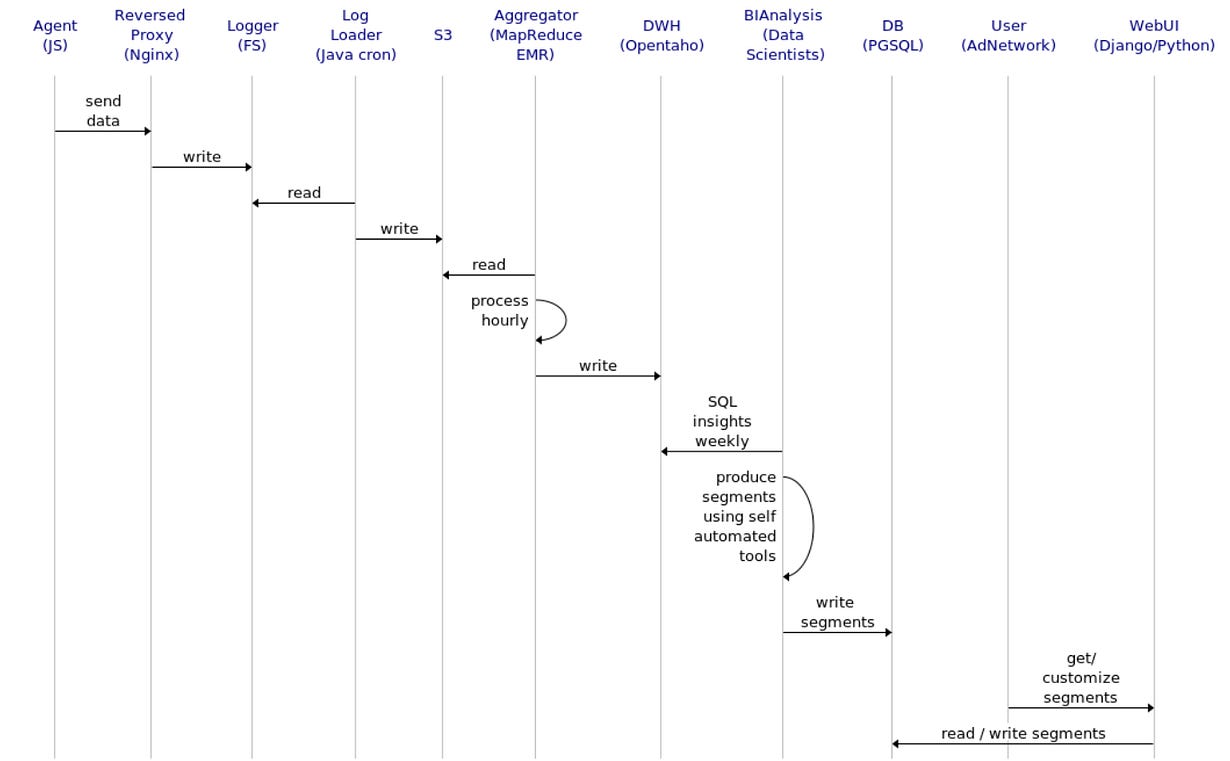
To produce Segments, we collected data periodically and processed it using our own lab’s products:
Deployment details
We baked our own AMIs, used python Fabric for delivery, and Puppet jobs to manage telemetry.
Munin daemons, Nagios agents, JMX, Managed JBs to collect all running stats
Maven/Nexus for packaging artifacts, running on a CI/CD Jenkins jobs.
Chef and Puppet for managing installation of DBs and other services for telemetry gathering.
A CDN to colocate web assets in order to reduce service latency across our Availability Zones.
A round-robin ELB and some Route53 configuration.
Lessons Learned
The solution achieved the goals initially set with outstanding performance and effectivity. However, during the R+D process for scaling parts of our storage enabling multi-tenancy features, we had some obstacles and setbacks:
Tried 1st using MongoDB for storing visitor profiles, but the volume for our setup was too big, the leader/follower architecture caused troubles to keep up once master-followers’s in-sync state was lost. It was good for simplicity and performance for the counters use case, and aggregating stats.
So we tried Cassandra, good for range queries and caching, but it required lot of vertical scaling for low latency and didn’t fit the usage profile for our investment, (learning curve, tech complexity, budget)
RabbitMQ without the persistence option was actually not fault-tolerant ready, to ensure real HA/FT required more vertical and horizontal scaling, for a use-case not worth it, we’d benefit having Kafka streams 5 years before 😏
All in all
The tech stack selection, like the implementation was a discovery journey to provide a better solution while coping with increasing workloads and incoming traffic, nothing was essentially perfect, but a work in progress, in a business that forged and still funds the internet growth.
We did a lot with the resources we had at that time. Because of our solutions, the start-up got acquired by an Ad Network.